علم رباتیک همیشه برای ما جالب بوده است. رباتهایی که روز به روز پیشرفتهتر میشوند و حتی تشخیص آنها از انسانها مشکل است. مثلا عروسکهای سیلیکونی که دقیقا ظاهری شبیه انسانها دارند و اگر صدا یا حرکت آنها را نبینیم، شاید در تشخیص ربات بودن آنها به مشکل بربخوریم. البته الان هم حرکت این رباتها آنقدر ظریف و شبیه به انسانها است که شاید در آینده مرزی بین انسان و ربات وجود نداشته باشد. حتی در هوش! بله هوش مصنوعی آنقدر پیشرفت کرده است که رباتها میتوانند فکر کنند، آموزش ببینند و یاد بگیرند. اینجا است که بحث جالب و پیشرفته ماشین لرنینگ مطرح میشود!
ماشین لرنینگ فرآیندی است که به کامپیوترها کمک میکند از پس وظایفی که انسانها انجام میدهند برآیند. از راندن خودروها گرفته تا ترجمه کردن گفتار، این رشته با کمک کردن به نرمافزار در فهم پیچیدگیها و آشفتگی جهان واقعی، انفجاری در زمینه کاربردهای هوش مصنوعی ایجاد کرده است. هدف اصلی ماشین لرنینگ تامین قابلیت یادگیری در ماشینها است تا بتوانند خودشان بدون نیاز به انسانها چیزها را یاد بگیرند.
هدف از این رشته چیزی نیست جز استفاده از قابلیتهای بالای ماشین یا کامپیوترها در یادگیری و انجام دقیق وظایفی که به آنها سپرده میشود. برای اینکه ماشین بتواند در بهترین حالت یادگیری قرار بگیرد لازم است که دادهها و اطلاعاتی در اختیار آن قرار بگیرد. این اطلاعات میتواند به شکل مجموعهای از فایلها و دادههایی باشد که به ماشین ارائه میشود. این اطلاعات همچنین میتواند با اجازه دادن به ماشین برای ارتباط با منابع داده و حتی دریافت اطلاعات و کنش تعاملی با جهان واقعی نیز تامین شود. در ادامه به جنبههای گوناگون ماشین لرنینگ پرداخته و سعی میکنیم جوانب مختلف آن را روشن کنیم.

به صورت خیلی خلاصه اگر بخواهیم بگوییم ماشین لرنینگ چیست، ماشین لرنینگ یا یادگیری ماشین یک نوع از هوش مصنوعی است که به یک سیستم امکان میدهد از روی دادهها یاد بگیرد و نه از روی برنامهنویسی دقیق. این رشته روی توسعه برنامههای کامپیوتری متمرکز میشود تا آنها را قادر سازد به دادهها دسترسی پیدا کرده و از آنها برای یادگیری خودشان استفاده کنند.
در یک سطح دیگر میتوان ماشین لرنینگ را فرایند آموزش دادن به یک سیستم کامپیوتری دانست تا بتواند هنگامی که اطلاعات مناسبی به آن داده میشود، پیشبینیهای دقیقی انجام بدهد. این پیشبینیها ممکن است تشخیص دادن اینکه یک تکه میوه در عکس، سیب یا پرتقال یا موز است، باشد، یا تشخیص یک دسته از افراد که در حال رد شدن از خیابان هستند باشد، یا اینکه در فلان جمله «دفتر» به معنای یک محل کار است یا به معنای محل یادداشت، و یا شناسایی محتوای یک ویدئو و تولید کپشن برای آن باشد.
تفاوت کلیدی یادگیری ماشین با نرمافزارهای سنتی در این است که در اینجا، یک برنامهنویس با کدهای دقیق کامپیوتری تفاوت سیبها با پرتقالها را برنامهنویسی نکرده، بلکه خود هوش مصنوعی این تفاوت را شناسایی میکند. به جای این کار، یک مدل یادگیری ماشینی تفاوت میوهها را بر اساس مجموعهای از دادهها، برای مثال حجم انبوهی از تصاویر تگشده میوههای مختلف مثل سیب، پرتقال، و موز یاد میگیرد. برای همین دادهها یا اطلاعات، و نه مقدار محدود بلکه حجم انبوهی از آنها، کلید اصلی امکانپذیری ماشین لرنینگ محسوب میشود.
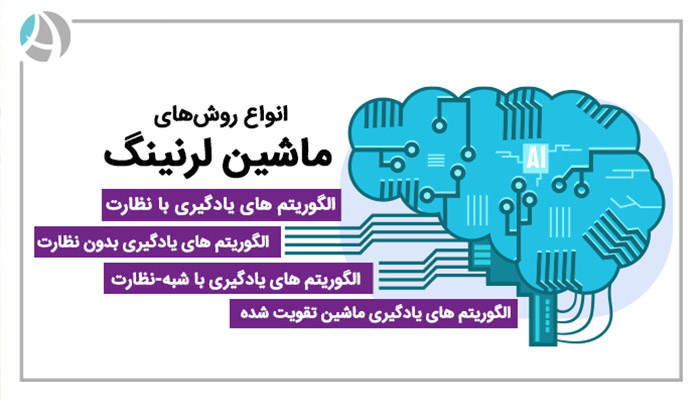
نحوه ارتباط برقرار کردن هوش مصنوعی یا عامل یادگیری ماشین با دادهها بر اساس مدلها و الگوریتمهای یادگیری ماشین مختلفی مشخص میشود. به صورت کلی، اغلب الگوریتمهای یادگیری ماشین به دو دسته اصلی تقسیم میشود:
این در حالی است که دستههای دیگری نیز در این طبقهبندی قرار میگیرند. از جمله این موارد میتوان به انواع یادگیری ماشین زیر اشاره کرد:
در ادامه هریک از این روش های ماشین لرنینگ را معرفی کرده و تفاوت آنها با یکدیگر که کاربردهای یادگیری ماشین بر اساس آنها مشخص میشوند را نشان خواهیم داد.

این رویکرد معمولا به ماشینها از طریق مثال آموزش میدهد. در حین آموزش و تمریندادن در روش با نظارت، حجم بسیار زیادی دادههای برچسب خورده به سیستم ارائه میشود. این دادهها ممکن است برای مثال شکلهای دستنویسی باشند که مشخص میکنند کدام عدد را نمایش میدهند. با دریافت مثالهای کافی، یک سیستم یادگیری ماشین با نظارت یاد میگیرد که خوشههای پیکسل و شکلهای مرتبط با هر عدد را شناسایی کرده و در ادامه قادر میشود اعداد دستنویس را تشخیص داده و شناسایی کند. به این ترتیب یاد میگیرد به خوبی فرق بین 7 و 8 یا 4 و 9 را تشخیص بدهد.
اما به هر حال لازم به ذکر است که تمریندادن و آموزش این سیستمها نیاز به حجم انبوهی از اطلاعات برچسب خورده دارد، و بعضی از این سیستمها برای تسلط یافتن روی یک وظیفه نیاز به میلیونها مثال دارند. در نتیجه، مجموعههای داده (Datasets) که برای آموزش این سیستمها به کار میروند بسیار بزرگ هستند. برای مثال مجموعه دادههای تصاویر باز گوگل شامل چیزی حدود 9 میلیون تصویر میشود.
فرآیند پر زحمت برچسب زدن دادهها کاری است که اغلب با استفاده از سیستمهای برونسپاری جمعی انجام میشود. برای مثال مجموعه داده ایمیجنت (ImageNet) که شامل بیش از 14 میلیون تصویر طبقهبندی شده است، در طول 2 سال و با کمک حدود 50.000 نفر از سراسر جهان انجام شده است. این در حالی است که به تازگی فیسبوک اعلام کرده مجموعه دادهای از تصاویر عمومی اینستاگرام به دست آورده که شامل بیش از 5/3 میلیارد تصویر میشود. این رویکرد، یعنی استفاده از تصاویر در دسترس عمومی برای یادگیری ماشین میتواند راهی برای برونرفت از دردسر برچسب زدن و ایجاد مجموعه دادههای دستی باشد.
در مقابل روش با نظارت، در یادگیری بدون نظارت از الگوریتمهایی استفاده میشود که وظیفه تشخیص پترن یا الگوهای داخل دادهها را انجام میدهند. این الگوریتمها سعی میکنند شباهتها را پیدا کنند تا با استفاده از آنها دادهها را به مقولههای مختلف طبقهبندی کنند. برای مثال هنگامی که از یک فروشگاه اینترنتی خرید میکنید از این الگوریتمها برای کنار هم قرار دادن آیتمهای مرتبط با جستجوی شما استفاده میشود. یا اگر از گوگل نیوز استفاده کنید متوجه میشوید که از این الگوریتمها برای کنار هم گذاشتن موضوعات مشابه و تاپیکهای مرتبط استفاده میشود.
این نوع الگوریتم برای شناسایی انواع مشخصی از داده طراحی نشده است، بلکه به سادگی به دنبال دادههایی میگردد که بر اساس مشابهت میتوانند کنار هم قرار بگیرند. همچنین میتواند موارد متفاوتی که بیرون از این دستهها قرار میگیرند را تشخیص بدهد.
ممکن است به واسطه اوج گرفتن استفاده از یادگیری ماشین با شبه-نظارت، اهمیت مجموعههای عظیم داده برای آموزش سیستمهای یادگیری ماشین در طول زمان کاهش پیدا کند. همان طور که از عنوان این روش مشخص است، در آن ترکیبی از یادگیری با نظارت و یادگیری بدون نظارت به کار برده میشود. این تکنیک از مجموعه کوچکی از دادههای برچسب خورده و در کنار مجموعه بزرگی از دادههای برچسب نخورده برای آموزش سیستم استفاده میکند. از دادههای برچسب خورده برای آموزش یک مدل ماشین لرنینگ استفاده میشود، سپس این مدل برای برچسب زدن دادههای بدون برچسب به کار برده میشود. به این فرایند برچسب زدن کاذب یا شبه-برچسب-زدن (pseudo-labelling) گفته میشود. سپس مدل بر اساس مجموعهای از دادههای برچسب خورده و برچسب نخورده آموزش میبیند.
استفاده از این روش اخیرا با ایجاد فریمورکهای جیایان (Generative Adversarial Networks)، که سیستمهای یادگیری ماشینی هستند که میتوانند از دادههای برچسب خورده برای تولید دادههای کاملا نو استفاده کنند، افزایش پیدا کرده است. هنگامی که یادگیری ماشین با شبه-نظارت به همان تاثیرگذاری یادگیری با نظارت شود، دسترسی به حجم بسیار بالای قدرت محاسبه ممکن است اهمیت بیشتری در یادگیری ماشین موفقیتآمیز پیدا کند تا دسترسی به مجموعه دادههای بزرگ برچسب خورده.
برای فهمیدن یادگیری ماشین تقویت شده میتوانید به نحوهای که یک نفر یاد میگیرد یک بازی قدیمی کامپیوتری را بازی کند توجه کنید. فرد در ابتدا نه قواعد بازی را میداند و نه میداند چطور باید آن را کنترل کند. در حالی که آنها ممکن است کاملا تازه وارد باشند، با نگاه کردن به ارتباط بین دکمههایی که فشار میدهند و اتفاقهایی که در تصویر میافتد، و امتیازی که در بازی به دست آورده یا از دست میدهند، کم کم یاد گرفته و بازی آنها بهتر و بهتر میشود.
یکی از کاربردهای یادگیری ماشین تقویت شده در شبکه-Q عمیق در مجموعه گوگل دیپ مایند است. این سیستم توانسته در مجموعه گستردهای از بازیهای ویدئویی قدیمی با استفاده از دوره یادگیری ماشین انسانها را شکست دهد. این سیستم با پیکسلهایی از هر بازی تغذیه شده و اطلاعات مختلف در مورد حالت بازی، مثل فاصله بین چیزهای مختلف در تصویر را تخمین میزند. سپس این موضوع که چطور حالت بازی و کنشهایی که در آن انجام میشوند با امتیاز نهایی ارتباط برقرار میکنند را بررسی میکند.
در نهایت با بررسی چندین باره روند بازی، سیستم به مدلی دست پیدا میکند که با استفاده از آن امکان به دست آوردن بالاترین امتیاز در بازی به وجود میآید.

در حالی که بسیاری از افراد تصور میکنند دو کلمه «ماشین لرنینگ» و «دیپ لرنینگ» را میتوان به جای هم به کار برد، اما در حقیقت این دو رشته کاملا از یکدیگر متفاوت هستند. به صورت کلی، Deep Learning یا یادگیری عمیق زیرمجموعهای از ماشین لرنینگ به شمار میآید، چرا که مفهوم فنی و کاربردهای عملی آن چیزی به جز یکی از انواع یادگیری ماشین نیست. به همین دلیل است که بسیاری از افراد این دو را با هم اشتباه میگیرند و به یک معنا به کار میبرند.
در اصل، کاری که یادگیری عمیق یا دیپ لرنینگ انجام میدهد ساختار بخشیدن به الگوریتمها به شکلی است که بتوانند یک شبکه عصبی مصنوعی (artificial neural network) ایجاد کنند، و این امکانی را فراهم میکند که الگوریتمها از طریق آن میتوانند هم یاد بگیرند و هم به شکل خودمختار تصمیمگیری کنند. این درست همان جایی است که تفاوت اصلی میان این دو تکنولوژی مطرح میشود.
یک برنامه کامپیوتری که با یادگیری ماشین طراحی شده باشد، به انسانی نیاز دارد که متوجه خطاهای آن شده و با اصلاح آنها مانع از تکرارشان در داخل سیستم شود. این در حالی است که یک مدل یادگیری عمیق خودش میتواند با استفاده از شبکه عصبی خودش تشخیص بدهد که وظیفهاش را با موفقیت یا با شکست به انجام رسانده است.

سیستمهای ماشین لرنینگ زیادی در همین دور و بر ما مشغول فعالیت هستند. بهتر است به یاد داشته باشیم که این رشته یکی از سنگبناهای اینترنت در معنای امروزی آن محسوب میشود.
هنگامی که از آمازون یا دیجی کالا خرید میکنید، این سیستمها پیشبینی میکنند خرید بعدی شما چیست یا به چه آیتمهایی ممکن است علاقه داشته باشید. هنگامی که یک ویدئو در یوتیوب یا آپارات تماشا میکنید، این سیستمها پیشبینی میکنند که از چه ویدئوهای دیگری ممکن است خوشتان بیاید.
در هر جستجوی گوگل از چندین سیستم ماشین لرنینگ استفاده میشود. هدف از این کار فهمیدن منظور شما و حدود دلالت جستجوی شما است، تا وقتی برای مثال به دنبال راه تعمیر شیر دستشویی هستید با تبلیغات شرکتهای لبنیاتی مواجه نشوید.
یکی از کاربردهای یادگیری ماشین که قدرت آن را به رخ میکشد انواع دستیارهای مجازی، مانند سیری شرکت اپل، الکسای آمازون، دستیار گوگل، و کورتانای مایکروسافت است. تمام این دستیارها به شکل گسترده از یادگیری ماشین برای شناسایی فرمانهای صوتی و توانایی فهم زبان طبیعی استفاده میکنند، همچنین به مجموعه دادههای بزرگی برای پاسخ به پرسشهای کاربران نیاز دارند.
گذشته از این کاربردهای بسیار آشکار، استفاده از این سیستمها تقریبا در هر صنعتی شروع شده است. از جمله این موارد میتوان به موارد کاربرد زیر اشاره کرد:
این فهرست به همین موارد محدود نبوده و هر روز دامنه کاربرد ماشین لرنینگ در صنعت بیشتر میشود. در نهایت این رشته راه را برای حضور روباتها و یادگیری آنها از انسانها باز میکند.
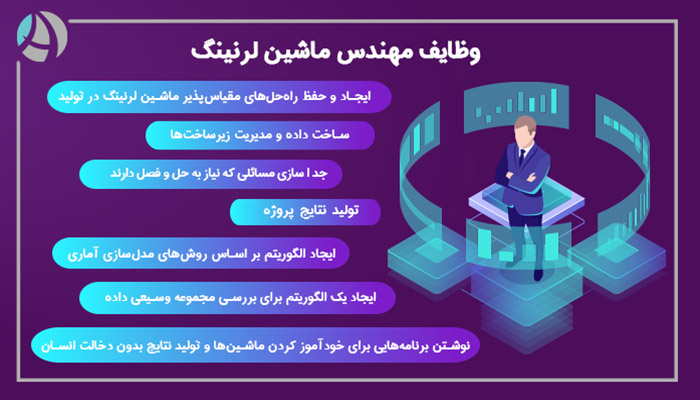
یک مهندس ماشین لرنینگ از خیلی جهات شبیه یک برنامهنویس است. اما تفاوت اصلی آنها این است که متخصص یادگیری ماشین باید برنامههایی برای خودآموز کردن ماشینها و تولید نتایج بدون دخالت انسان بنویسد. به طور کلی یک متخصص ماشین لرنینگ نقشهای مختلفی برای ایفا کردن دارد.
مثلا میتواند الگوریتمی ایجاد کند که مجموعه وسیعی از دادهها را بررسی کرده و بر اساس آن روندها و الگوها را مشخص کند. مثلا شرکت آمازون میتواند نوتیفیکیشنها را بر اساس سابقه خرید و مرور یک کاربر به خریداران دیگر هدایت کند. تولید نتایج پروژه و جداسازی مسائلی که نیاز به حل و فصل دارند، از وظایف دیگر این متخصص است. ساخت داده و مدیریت زیرساختها هم اهمیت زیادی دارند. یکی دیگر از نقشهای متخصص ماشین لرنینگ، مدلسازی دادهها و استراتژیهای ارزیابی برای یافتن الگوها و پیشبینی موارد دیده نشده است. در نهایت ایجاد الگوریتم بر اساس روشهای مدلسازی آماری و ایجاد و حفظ راهحلهای مقیاسپذیر ماشین لرنینگ در تولید هم اهمیت دارد.
افرادی که در این زمینه تخصص داشته باشند، میتوانند تبدیل به مهندس یادگیری ماشین، سرپرست علوم داده، دانشمند ماشین لرنینگ یا دانشمند داده NLP شوند.
چه یک دانشمند داده باشید یا یک توسعهدهنده نرمافزار، یک گواهینامه تخصصی در زمینه یادگیری ماشین شما را به یک نقش جدید مهیج و اساسی در صنایع میرساند. یادگیری این شاخه علمی در محل کار نسبتا سخت است. به همین دلیل میتوانید آموزش این رشته را انتخاب کنید و متخصصان دیگری در این زمینه تربیت کنید. اگر افراد علاقهمند به این رشته را ملاقات کردید، به آنها گوشزد کنید که حوزههای علمی زیر را جدی بگیرند و تمرکز خود را روی یادگیری آنها بگذارند. اگر خودتان تسلط کافی دارید، آموزش به آنها را بر عهده بگیرید.
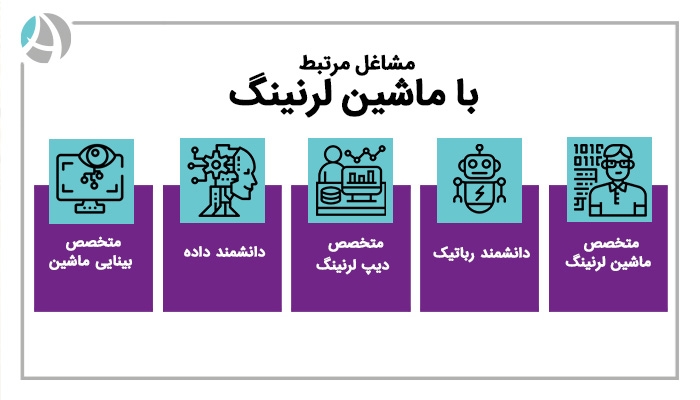
در حال حاضر متخصص ماشین لرنینگ محبوبترین و پرتقاضاترین شغل در زمینه هوش مصنوعی است. مشاغل مختلفی در ارتباط با این تخصص وجود دارد. مشاغلی مثل:
منبع: kdnuggets | hindustantimes








محمد اسماعیل پور
3 سال پیش